
05
2025

5月9日,诺亚鸿云联合中国开放指令生态(RISC-V)联盟在北京宣布成立RISC-V国产智算体系结构创新专业组,现场300多人参与会议。诺亚鸿云一举发布5款采用AGC架构设计的智算新品,从支持双卡到支持20卡不等,成为全球首家单机全面适配DeepSeek各模型尺寸产品的企业。
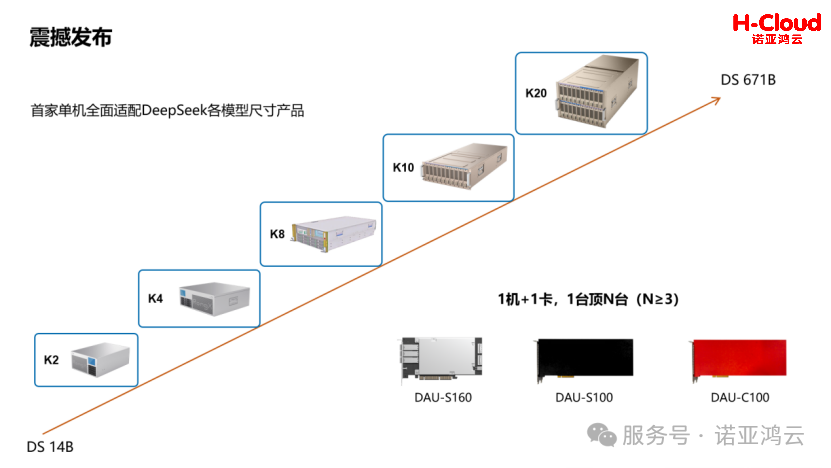
其中,入门级的K2支持双卡,体积小巧、超静音(噪音低于55分贝),预置DeepSeek 32B模型服务、推理环境及RAG环境,非常适合办公场景部署;旗舰级的K20单机可支持20卡,通过创新的张量并行技术,完美运行满血版 DeepSeek 671B全量模型。较于传统方案则需要4台8卡机器组网,技术复杂、成本高、运维难度大。K20基于独立全信创体系,支持国内外多种形态的GPU算力卡及主流CPU处理器,同时适配DeepSeek、Qwen、LLama、ChatGLM等国内外主流开源AI大模型。

图:支持20卡(16生产卡+4热备卡)的K20现场点亮
诺亚鸿云CTO石旭在主题报告中分享了K20背后的架构创新理念与核心技术。他谈到,芯片、系统和软件是计算机体系结构的三大关键要素。只有在体系结构层面进行高维度的创新,才能打破成本、效率、灵活性“不可能三角”的魔咒,让GPU发挥更大算力效率,同时更具成本优势和灵活的适应性。

图:AGC是面向AI时代的计算机体系结构
在高性能计算(HPC)、大模型训练/推理等场景应用中,与CPU相比,GPU作为核心加速计算部件,具有功耗更高、运行温度更高、故障率更高等“三高”特征,进而对GPU算力卡的生产级可用性、运维便捷性、使用寿命构成严重挑战。有数据表明,某国外著名GPU在非7X24小时使用情况下的故障率为1-3%,在高负荷场景下故障率高达5-8%。由于长期处于高温高能耗状态,GPU的平均寿命仅有1-3年。对普通架构智算整机而言,单卡故障会直接导致整机停止服务,恢复时间需2小时以上。
针对上述挑战,诺亚鸿云技术团队另辟蹊径,立足AGC架构设计理念,实现了全球首创的GPU热插拔、GPU-RAID高可用、GPU节能延寿等三大技术突破。通过GPU Box设计,更换GPU卡就像换硬盘一样简单,运维时间从至少2小时缩短到1分钟,极致提升运维效率,保障业务连续性;通过GPU-RAID技术,类似磁盘阵列的冗余设计,使单机可用性从传统架构的85%跃升至99.99%,极大提升生产环境下智算系统的SLA服务水平;通过GPU算力卡单点电源管理技术,构建细粒度能耗管理体系,让GPU在非工作时段由系统自启休眠模式,降低功耗和电费,并有效延长GPU卡的使用寿命。另外,通过单张GPU算力卡与100G至400G网卡绑定技术(不占用CPU性能),实现单机2T至8T通信墙,支撑构建万卡矩阵组网。
诺亚鸿云提出的AGC架构与技术突破,已经获得多家上下游伙伴与企业用户的认可。来自航天联志、燧原科技、晓软科技的嘉宾分别介绍了与诺亚鸿云的合作成果。其中,航天联志基于诺亚鸿云技术的通算/智算系列产品,已经在油田、政务、涉密部门实现部署应用;燧原科技表示对于燧原S60的诺亚鸿云一体机DeepSeek 671B满血版,经优化测试后获得了极好的综合性能,相较于ACC结构,节省了50%的硬件资源;晓软科技不仅将诺亚鸿云的AGC智算方案引入PCB行业20强企业科翔股份智能报价+chatBI智能问数场景,还推出了基于超融合DAU数据处理器加速卡的信创服务器方案,提升IO性能3-10倍,降低硬件投资及运营成本50%以上。
为进一步推广AGC架构,吸引更多企业进行协同创新,诺亚鸿云选择将所有知识产权面向CPU、GPU、整机厂商以及RISC-V联盟成员单位进行开放、共享。在此次会议上,RISC-V联盟国产智算体系结构创新专业组也宣告成立,成为该联盟旗下七大专业组之一。

图:RISC-V国产智算体系结构创新专业组成立仪式
在全球RISC-V生态高速发展、RISC-V高性能处理器不断取得技术突破的态势之下,RISC-V+AI正成为新的产业共识,有望为AI推理算力市场带来新的组合方案。在这一背景下,基于RISC-V的国产化智算体系架构创新机会巨大,国产智算创新体系专业组的成立可谓恰逢其时。中国开放指令生态(RISC-V)联盟秘书长包云岗在致辞中对专业组提出了三点期望:一是坚持开源开放,秉承RISC-V初心,推动技术共享和协作创新,二是聚焦国产智算,结合中国市场需求,打造真正可自主演进的解决方案,三是汇聚行业力量,联合产学研各界共同构建繁荣的RISC-V生态体系。

图:中国开放指令生态(RISC-V)联盟秘书长包云岗致辞
诺亚鸿云CTO石旭在演讲中也谈到,未来还有很多体系结构方面的技术需要协同专业组一起协作解决,比如部件级芯片级高速传输技术、国产开源人工智能框架等。目前联盟内部已经启动“延安开源框架”研发项目,将全方位支持国产GPU,着力解决GPU深度优化、全局缓存共享、全链路优化、大模型安全、训推效率提升等5个方面的问题。
在圆桌论坛环节,RISC-V副秘书长张松就国产AI发展和七位行业专家展开深度对话,诺亚鸿云首席科学家张彦朝指出:“AGC架构已在国内多个重点行业验证,推理效率提升3倍以上。”兆松科技CEO范泽分享:“我们开发的RISC-V专用编译器可将CUDA迁移损耗控制在15%以内。”信创海河实验室主任王涛强调:“要通过开源协作突破技术壁垒,构建自主可控的AI生态。”

图:圆桌论坛

立即联系专家团队,为您定制解决方案